Web Scraping vs API
May 27, 2019
When determining how to get content off a web page the answer will almost certainly depend on how the content itself is being loaded.
When to scrape
If the content you are after is loaded with the page, meaning it was rendered from the server, you can most likely scrape it.
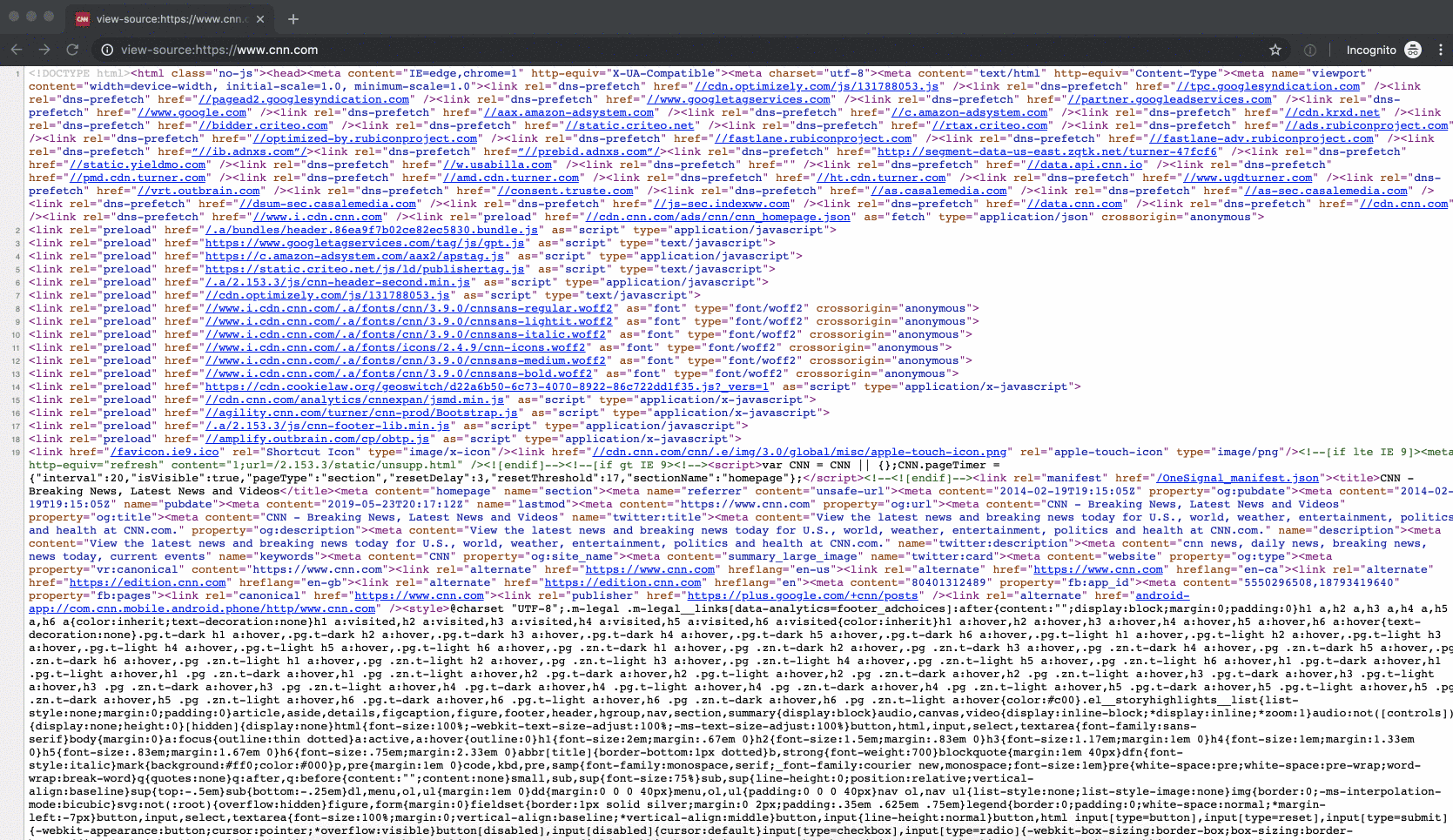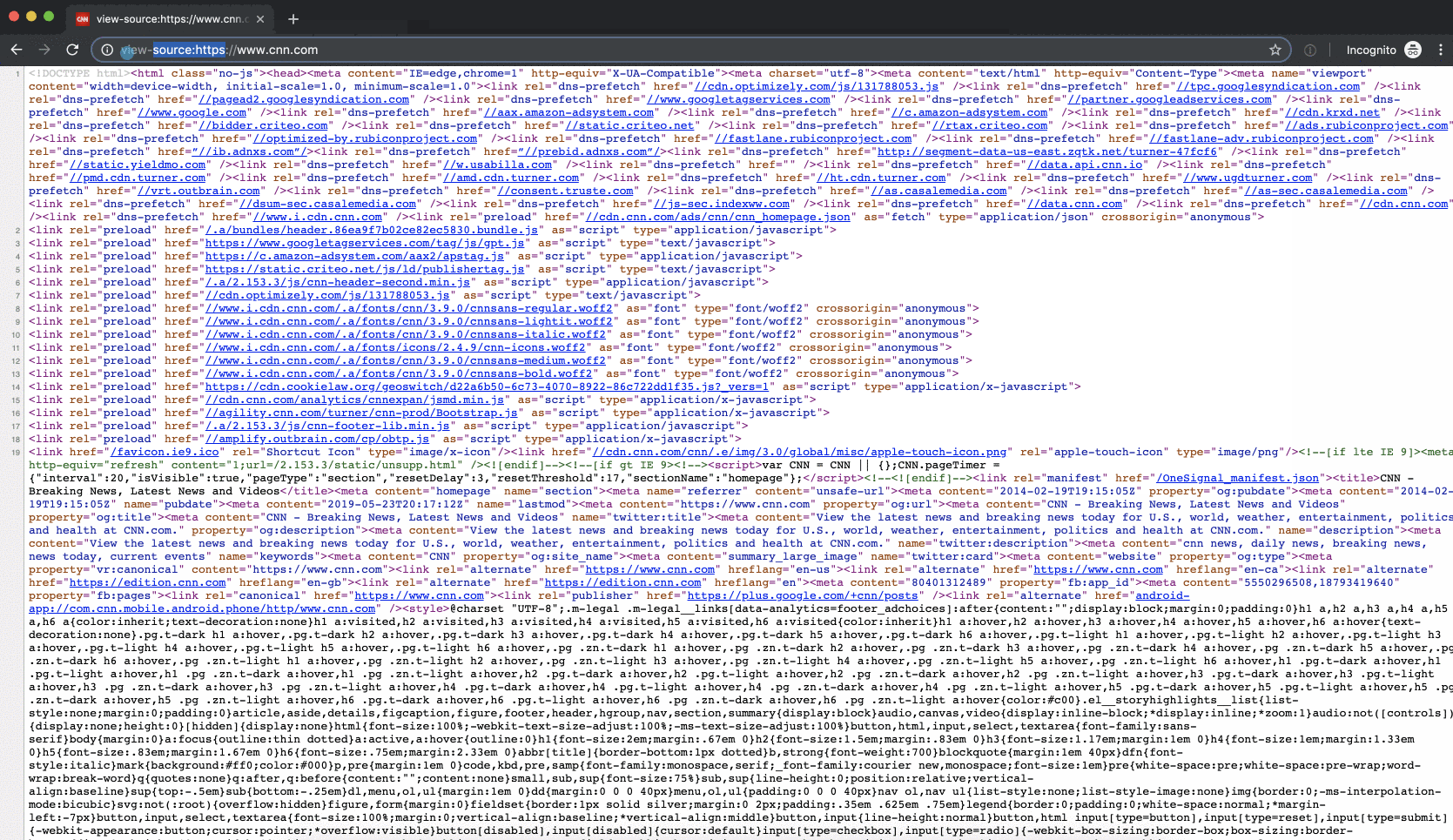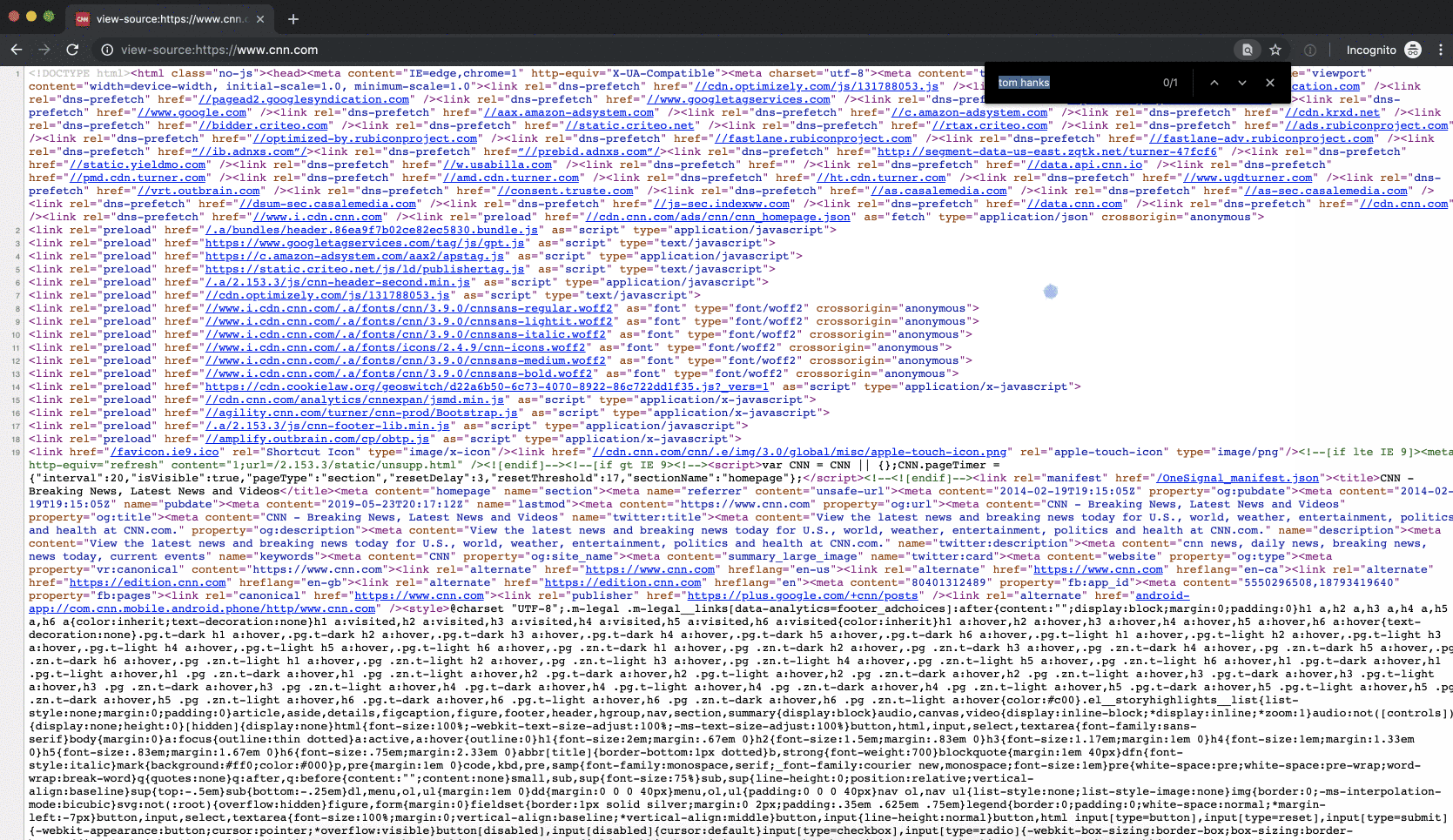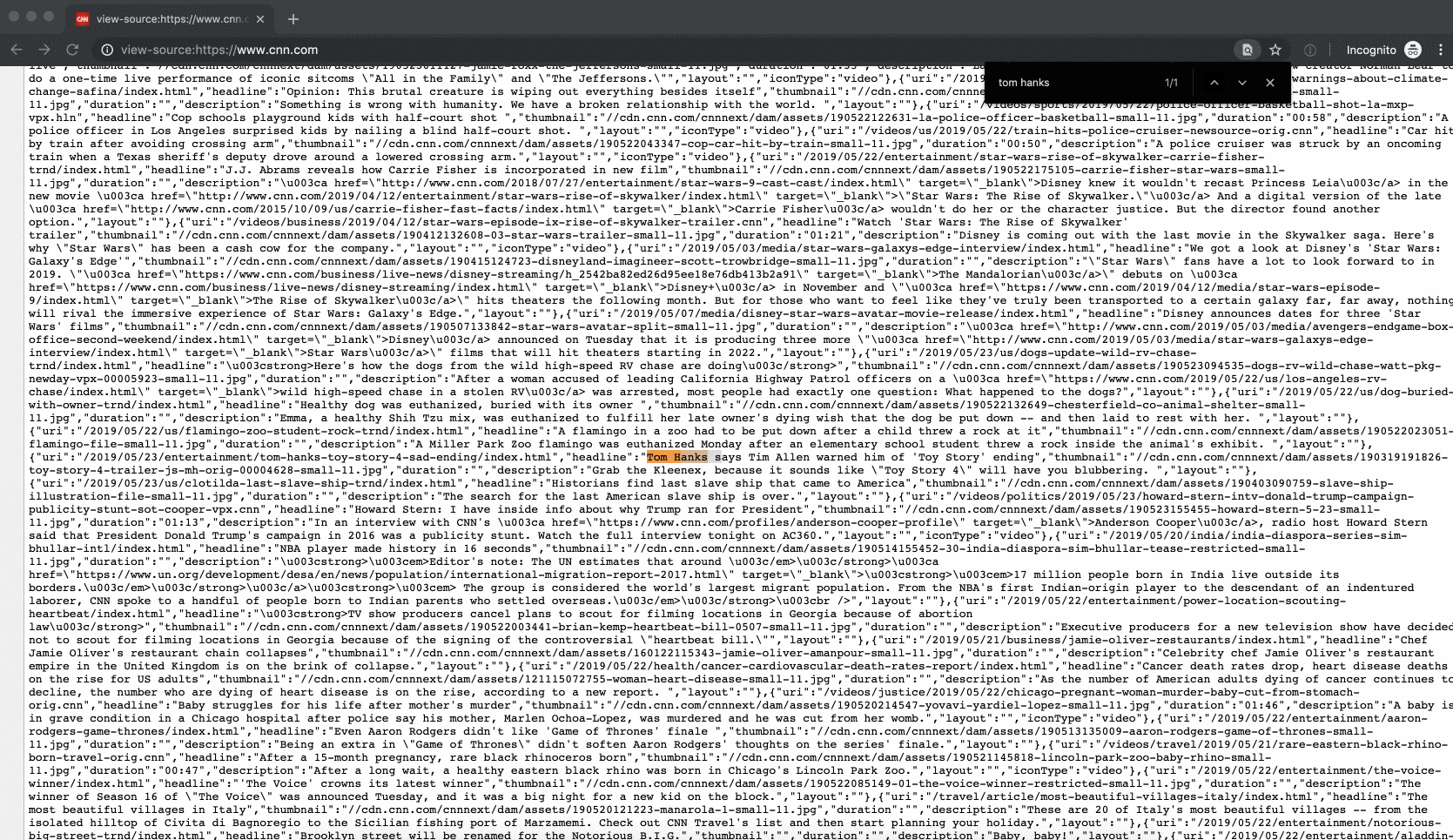
How do you know if the content was server rendered? Good question. This is when you need to rely on your browsers developer’s tool. In Chrome, you can inspect any web page and see its “source” by doing a right mouse click and clicking on View Page Source. This will open up a new tab with all of the HTML, CSS, and JS that was initially loaded from the server. Now hit cmd+f to do a quick search for the text in question. If you can find the pieces of text you are after, chances are you can scrape it.
While scraping can be a quick way to get at content, it does have a weakness. Because you are quite literally extracting the raw HTML structure of the page, any major change to its composition can potentially break the code you have written. Consider an API if your site structure is changing frequently.
When to use an API
If the content you want is loaded after the page rendered or is otherwise missing from the page source, you will most likely need an API.
Sites that use JS frameworks to fetch and compose content are notoriously difficult to scrape. This is because when the page first loads, the content is not part of the page. It only gets added after being fetched from a data source (API) and injected into the HTML source.
Another reason why you may want to use an API is for speed and reliability. API’s are written by developers for developers. Meaning there is an explicit understanding that software relies on it for retrieving content. Naming conventions and best practices are strictly adhered to. This results in a more stable application.

Personal blog of Roger Rodriguez
Words & Code